
我们对VLA通常期望强大的语言遵循能力以及其带来的泛化能力,然而在实际实验里,L的表现并不理想。现在的VLA似乎更像是VA,L被V淹没,实际上只是一个参数量更大一点的模仿学习罢了。
VLA真正能理解语言吗,还是只把L当作长一点的id?
遵循这个疑问,在这里更新一些我读过的相关论文。
ECoT#
Question#
- 基于模仿学习的机器人模型难以在训练数据外泛化
- 是否能将CoT引入机器人模型来提升性能?
Motivation#
- 大模型CoT在机器人上的直接迁移效果并不好
- CoT在推理时缺乏对低层控制的观察与理解
Data#
- 基于BridgeV2,对其中的数据手动标注,用PrimisticVLM进行场景理解与分析
- 用DINO对目标设定图像框
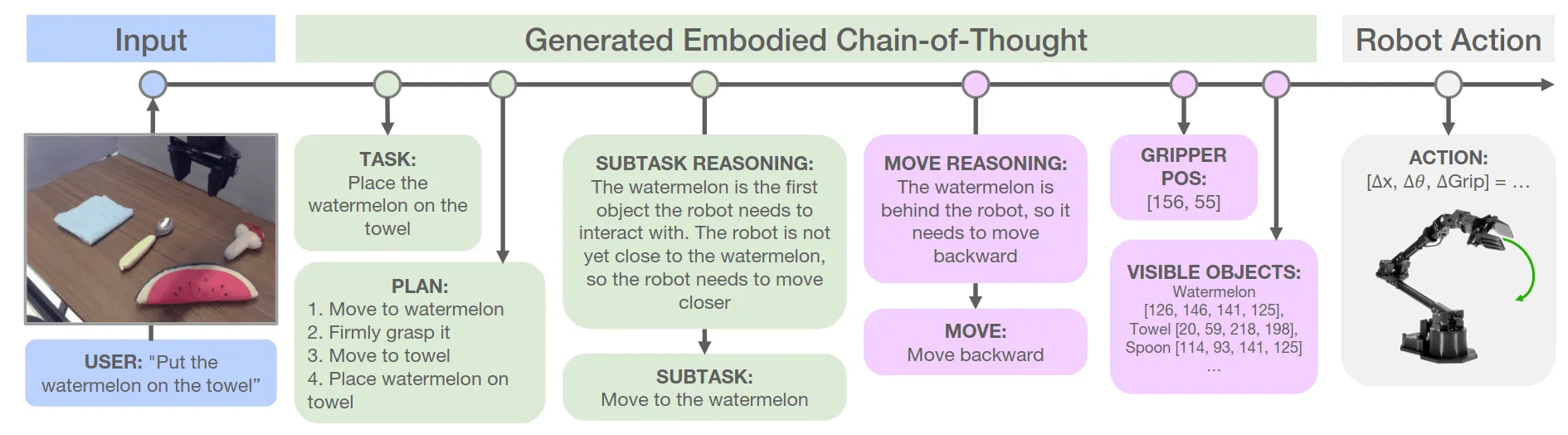
- OWLv2和SAM依据机器人状态和夹爪位置计算运动原语
- 最后用Gemini1.0总结并设定推理链,拼接成长文本输入
Arch#
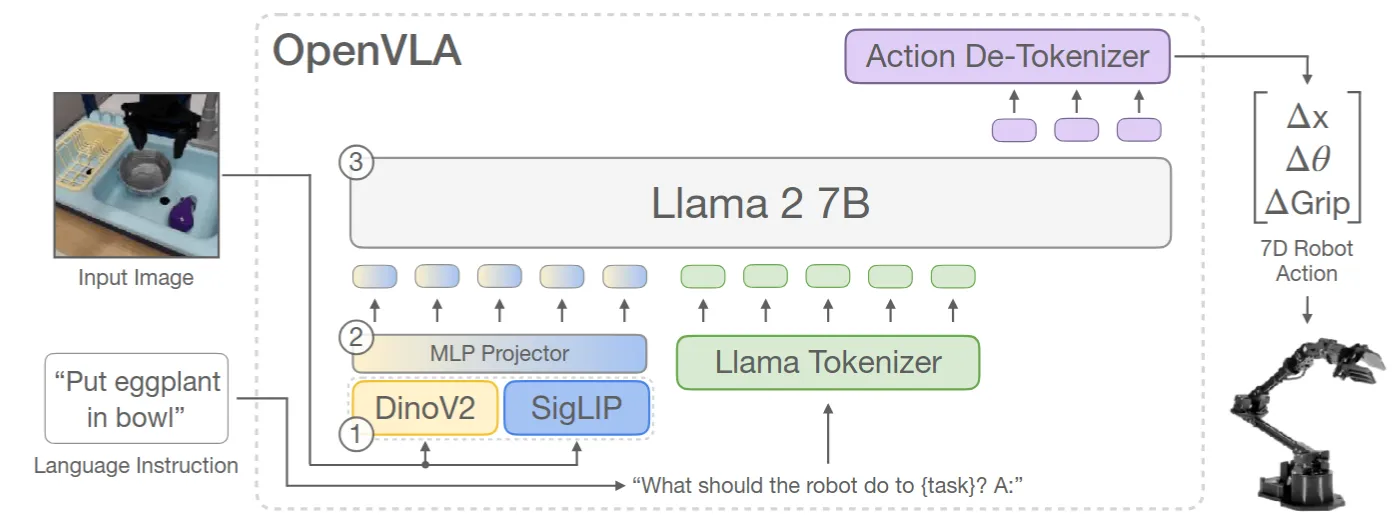
Backbone: OpenVLA-7B
Prompt: task+plan+subtask+move+gripper&obj+action
Loss&Reward: 自回归交叉熵损失
Experiments#
Benchmark:基于WidowX,任务包括OOD objects + OOD instructions等
Ablation:
- Naïve CoT vs. ECoT
- 在加入人类干预的情况下(允许一次中断给出人类反馈):Naïve CoT vs. ECoT
- 推理加速
Conclusion#
- 通过ecot方法,在不增加演示数据的情况下,显著提升了策略的泛化能力
- 发现推理链通常与执行的动作有很强的相关性
- ecot方法导致的大量推理token显著增大了推理延迟
- 推理的结构与深度均固定,且开环执行,无法根据任务难度与环境反馈动态调整